have a batch script that downloads and zips studies from orthanc container (orthancteam/orthanc:25.2.0) - the offending line is:
curl -s -u “$ORTHANC_USER:$ORTHANC_PASS” “$ORTHANC_URL/studies/$STUDY/archive” -o “$ZIP_FILE”
typical study size is between 100 to 600 MB. host machine has 8 GB RAM. during the loop, orthanc memory grows and grows until eventually freezing. MALLOC_ARENA_MAX is set to 1.
any tips on how to control this?
thanks in advance
Hello Olivert,
The full list of glibc environment variables that can impact memory can be found here
You might want to try play with the MMAP threshold and the trim settings (that can trigger “GC”)
Please let us know if you manage to impact the memory behavior!
Hi,
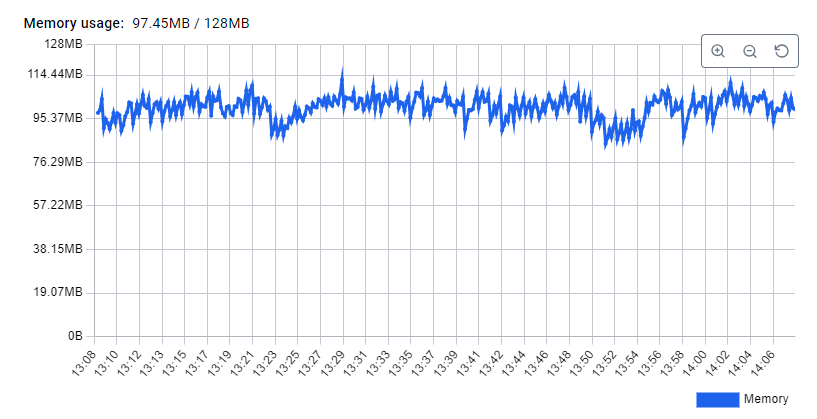
I have just run a test and observe quite a stable memory usage:
Here, I have limited the container memory to 128MB since I’m using small studies:
services:
orthanc:
image: orthancteam/orthanc:25.4.2
volumes:
- "orthanc-storage:/var/lib/orthanc/db"
ports: ["8045:8042"]
environment:
ORTHANC_JSON: |
{
"AuthenticationEnabled": false,
"MaximumStorageCacheSize" : 10
}
deploy:
resources:
limits:
memory: 128M
volumes:
orthanc-storage:
And I’m testing with this python script:
from orthanc_api_client import OrthancApiClient
from orthanc_tools import OrthancTestDbPopulator
import tempfile
import pprint
import os
o = OrthancApiClient("http://127.0.0.1:8045")
o.is_alive()
if False:
count = 1
while True:
print(f"generating new study {count}")
p = OrthancTestDbPopulator(api_client=o, studies_count=1, worker_threads_count=8)
p.execute()
studies_ids = o.studies.get_all_ids()
study_id = studies_ids[0]
# anonymized_study_id = o.studies.anonymize(study_id, delete_original=False)
with tempfile.NamedTemporaryFile() as file:
print(f"downloading study in {file.name}") # the file shall be deleted automatically
o.studies.download_archive(study_id, file.name)
print("deleting study")
o.studies.delete(study_id)
count += 1
else:
studies_ids = o.studies.get_all_ids()
if len(studies_ids) == 0:
print("uploading")
uploaded_instances_ids = o.upload_folder("/mnt/c/Users/Alain/o/dicom-files/20CT-instances/")
studies_ids = o.studies.get_all_ids()
study_id = studies_ids[0]
count = 0
while True:
print(f"anonymizing study {count}")
anonymized_study_id = o.studies.anonymize(study_id, delete_original=False)
with tempfile.NamedTemporaryFile() as file:
print(f"downloading study in {file.name}") # the file shall be deleted automatically
o.studies.download_archive(anonymized_study_id, file.name)
print("deleting study")
o.studies.delete(anonymized_study_id)
count += 1
So, please, in order for us to investigate, modify this sample setup until you can reproduce a memory leak.
Alain.