Hello All,
Is there any REST api available in Orthanc to locate the physical path of a DICOM file?
Thanks and regards,
Mathew
Hello All,
Is there any REST api available in Orthanc to locate the physical path of a DICOM file?
Thanks and regards,
Mathew
Hi Mathew!
Yes, there is a way. Sort of.
I’ll try and summarise the process:
The image below illustrates the process:
I’ve got little time right now so please do apologise the “rushy” e-mail.
HTH
Thank you Luiz, appreciate it.
This is really informative and helpful.
Hello,
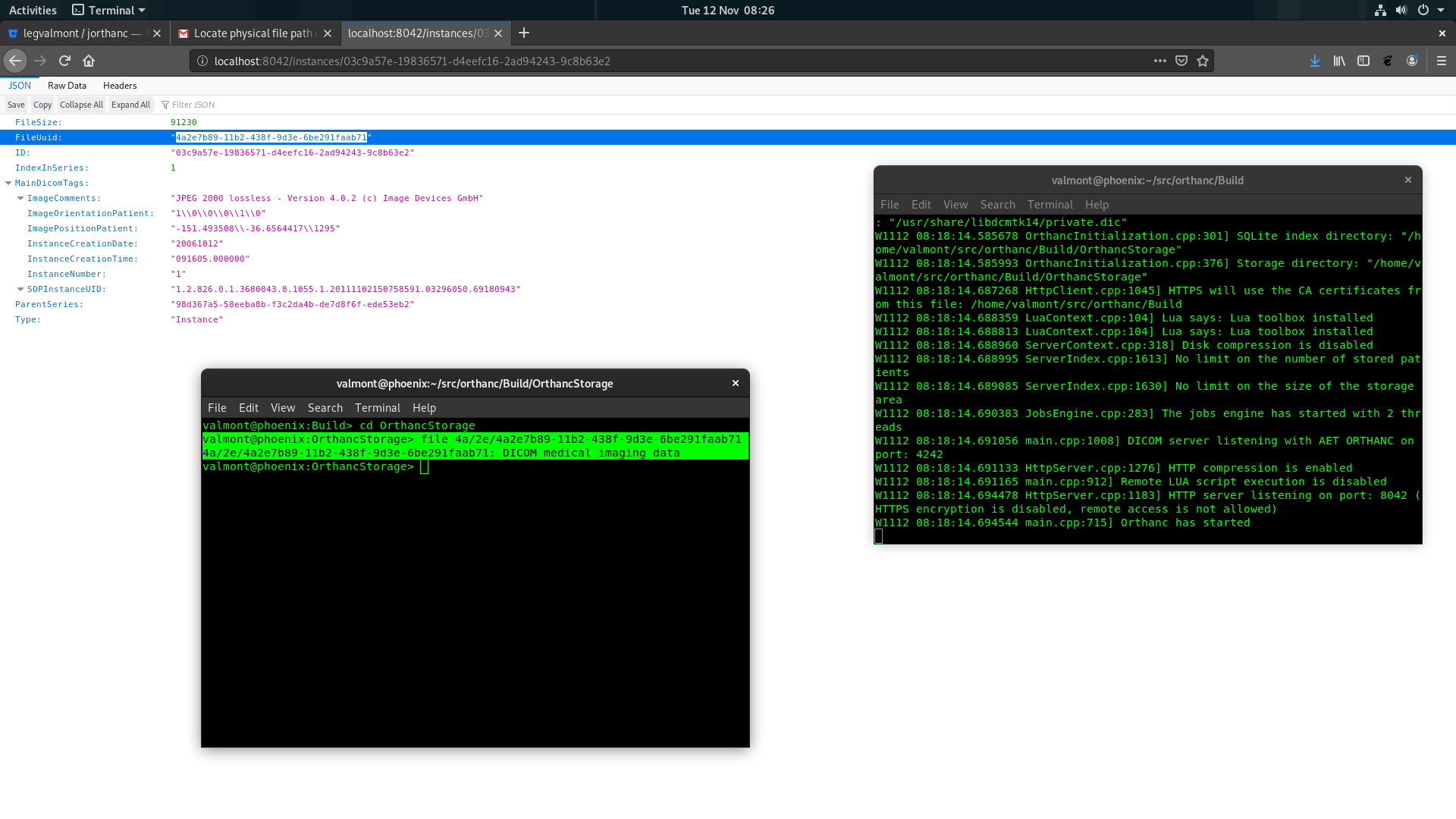
Please note that you shouldn’t directly access the storage area, except in very specific scenarios, for reasons explained here:
https://book.orthanc-server.com/faq/orthanc-storage.html#direct-access
You can use the “/instances/…/export” URI in the REST API to save the DICOM file associated with one instance onto the filesystem of the computer that runs Orthanc. Here is a full example to write the instance to the file “/tmp/instance.dcm”:
$ curl http://localhost:8042/instances/19816330-cb02e1cf-df3a8fe8-bf510623-ccefe9f5/export -X POST -d ‘/tmp/instance.dcm’
HTH
Not sure if it’s appropriate to post follow up questions here but basically I want to move archive’s after they are created via OnJobSuccess to specific folders outside of Orthanc (possibly elsewhere later). Would you still recommend using the API for this because wouldn’t it be faster to be able to use the cp command on ubuntu? Speed is a factor here. To be fair I haven’t tested the two approaches but I most likely will. Also if the faster way is to use cp rather than the API to copy an archive (these can be gigs in size) what is the folder structure based on jobId or how does that work? If my only choice is to use the API I can settle with that but I would like to weigh my options.
Hi, Richard
I’m not sure I got your requirement right.
If it’s just copying, I’d stick with Sébastien’s adivce. That way your code is more resilient to changes in Orthanc’s code base.
If you want todo something else like sending over SCP, then you might want to use a different storage plugin. For instance, one that you know in advance where the file will be recorded. Then your cp will be straightforward in an OnStoredInstance.
If, on the other hand, you want to move the file, then I’d suggest disabling storage altogether in Orthanc whilst implementing a custom ReceivedInstanceFilter. With that you’ll be able to write the file where you want it to be in the end and Orthanc will make sure it works just as an index.
HTH
So I’ve tried Sebastian’s advice and it seems that the jobs are getting pruned prematurely which doesn’t allow me to download them. I must be doing something else wrong here but I don’t really know where I’m going wrong. I’m using Orthanc version 1.5.8 and some helpful code snippets are the following:
function OnStablePatient(patientId,tags,metadata) RestApiPost( '/tools/create-archive', '{"Synchronous": false, "Resources": [' .. patientId .. ']}' ) --the job exists after this end
function OnJobSuccess(jobId) local JobDetails = ParseJson(RestApiGet('/jobs/' .. jobId)) if (JobDetails.Type == 'Archive') then -- by the time i get here my job no longer exists! os_execute('cd somepathHere && curl http://localhost:8080/jobs/' .. jobId .. '/archive -o somefilename.zip') end end
I don’t understand why my job is no longer there as I am not making any other API calls, I do run this on every patient update however and that might be why it’s acting strange. I might be able to build a watered down (not theoretical) example and put that here but any advice in the mean time would be appreciated. I suppose I’m more concerned about the storage of archives rather than instances themselves (archives generated from my api calls). My goal is to pre-zip and over-write on every update so when the user asks for the archive it’s ready for them. In my actual code my OnStablePatient is making a call using an array of series ids rather than the patient id. In my configuration I allow 10 jobs to exist, but this happens even with just 1 job.
IMHO, you should simply set the “MediaArchiveSize” configuration option of Orthanc to a higher value (it defaults to 1):
https://bitbucket.org/sjodogne/orthanc/src/Orthanc-1.5.8/Resources/Configuration.json#lines-487
So I have figured out the problem, and while I did up the MediaArchiveSize like you suggested (thank you) I’ve also found that this like of code in OnJobSuccess was problematic
os_execute('cd somepathHere && curl [http://localhost:8080/jobs/](http://localhost:8080/jobs/)' .. jobId .. '/archive -o somefilename.zip')
This caused the process to hang and for the job to be deleted, after taking that line out i see my job again, I’ll just move the “archive copy” logic to be after Job Success and see if that works for now. Thanks all for your suggestions/help so far.