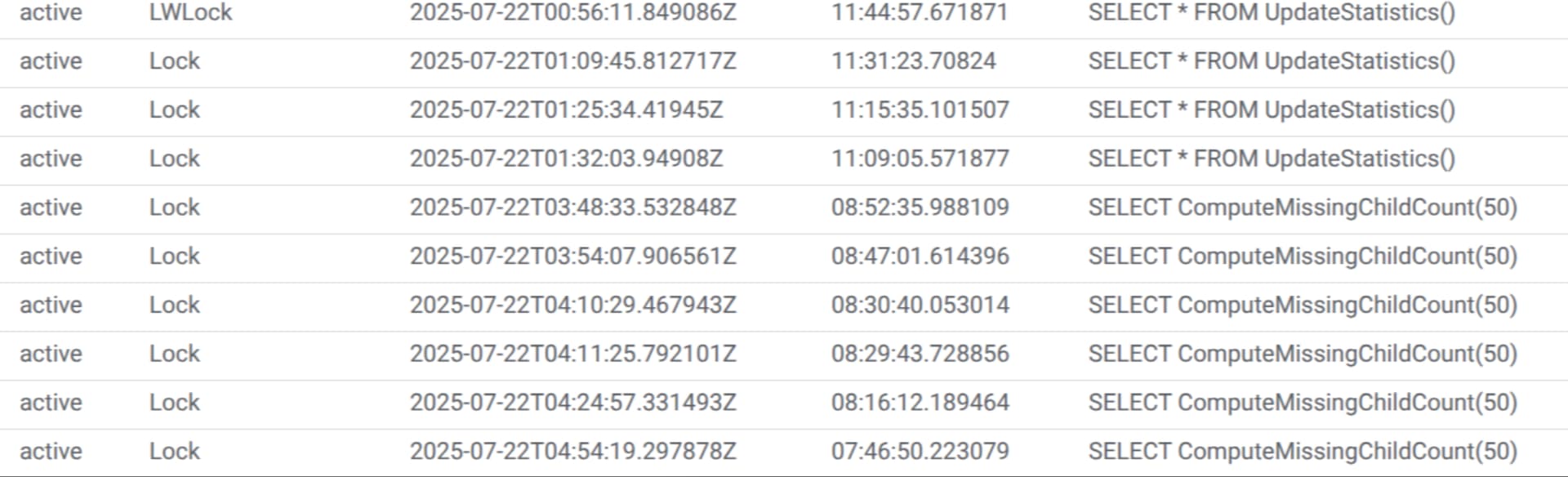
Hi, yesterday we upgrade our Orthanc instance from the docker orthancteam/orthanc 24.9.1 to 25.4.2, including the update to orthanc 1.12.7 and the Orthanc SQL plugin.
After this, we are measuring a notable increase in the response time of some queries. Last monday avg response time was below 1 second, and now over 10 seconds. There request include:
/dicom-web/studies?limit=101&offset=0&fuzzymatching=false&includefield=00081030%2C00080060&StudyInstanceUID=REDACTED
and
/dicom-web/studies?00100020=*REDACTED*&limit=101&offset=0&fuzzymatching=false&includefield=00081030%2C00080060.
At the same time, we see an increase in the CPU usage of the database, in this case, Postgres Google Cloud SQL. Right now, it keeps at 100% for about 12 hours.
I include an incomplete orthanc.json file:
orthanc.json
{
"Name": "Orthanc Incoming",
"StorageDirectory": "/var/lib/orthanc/db",
"IndexDirectory": "/var/lib/orthanc/db",
"TemporaryDirectory": "/tmp/orthanc/",
"StorageCompression": true,
"MaximumStorageSize": 0,
"MaximumStorageCacheSize": 0,
"ZipLoaderThreads": 4,
"ExtraMainDicomTags": {
"Instance": [
"Rows",
"Columns",
"ImageType",
"SOPClassUID",
"ContentDate",
"ContentTime",
"FrameOfReferenceUID",
"PixelSpacing",
"SpecificCharacterSet",
"BitsAllocated"
],
"Series": [],
"Study": [],
"Patient": []
},
"Warnings": {
"W001_TagsBeingReadFromStorage": true,
"W002_InconsistentDicomTagsInDb": false
},
"MaximumPatientCount": 0,
"LuaScripts": [],
"Plugins": [
"/usr/share/orthanc/plugins",
"/usr/local/share/orthanc/plugins"
],
"ConcurrentJobs": 40,
"HttpServerEnabled": true,
"HttpDescribeErrors": true,
"HttpCompressionEnabled": true,
"DicomServerEnabled": true,
"DicomCheckCalledAet": false,
"DefaultEncoding": "Latin1",
"DeflatedTransferSyntaxAccepted": true,
"JpegTransferSyntaxAccepted": true,
"Jpeg2000TransferSyntaxAccepted": true,
"JpegLosslessTransferSyntaxAccepted": true,
"JpipTransferSyntaxAccepted": true,
"Mpeg2TransferSyntaxAccepted": true,
"RleTransferSyntaxAccepted": true,
"UnknownSopClassAccepted": false,
"DicomScpTimeout": 120,
"DicomModalities": {},
"DicomModalitiesInDatabase": true,
"DicomAlwaysAllowEcho": true,
"DicomAlwaysAllowStore": true,
"DicomCheckModalityHost": false,
"DicomScuTimeout": 120,
"OrthancPeers": {},
"OrthancPeersInDatabase": false,
"HttpProxy": "",
"HttpVerbose": false,
"HttpTimeout": 600,
"HttpsVerifyPeers": true,
"HttpsCACertificates": "/etc/ssl/certs/ca-certificates.crt",
"UserMetadata": {},
"UserContentType": {},
"StableAge": 60,
"StrictAetComparison": false,
"StoreMD5ForAttachments": true,
"LimitFindResults": 100,
"LimitFindInstances": 100,
"LogExportedResources": false,
"KeepAlive": true,
"TcpNoDelay": true,
"HttpThreadsCount": 200,
"DicomThreadsCount": 100,
"StoreDicom": true,
"DicomAssociationCloseDelay": 5,
"QueryRetrieveSize": 200,
"CaseSensitivePN": false,
"LoadPrivateDictionary": true,
"Dictionary": {},
"SynchronousCMove": true,
"JobsHistorySize": 1000,
"SaveJobs": false,
"OverwriteInstances": false,
"MediaArchiveSize": 15,
"StorageAccessOnFind": "Never",
"MetricsEnabled": true,
"DatabaseServerIdentifier": "@@@DATABASE_SERVER_IDENTIFIER@@@",
"PostgreSQL": {
"EnableIndex": true,
"EnableStorage": false,
"IndexConnectionsCount": 50,
"Host": "@@@POSTGRES_HOST@@@",
"Port": 5432,
"TransactionMode": "ReadCommitted",
"Database": "@@@POSTGRES_DB@@@",
"Username": "@@@POSTGRES_USER@@@",
"Password": "@@@POSTGRES_PASSWORD@@@"
},
"DicomWeb": {}
}
Do you have some intution to where is this problem coming from? Maybe is there a way to fix this behaviour before we can find a final solution?
We are eager to provide further information.
Thanks