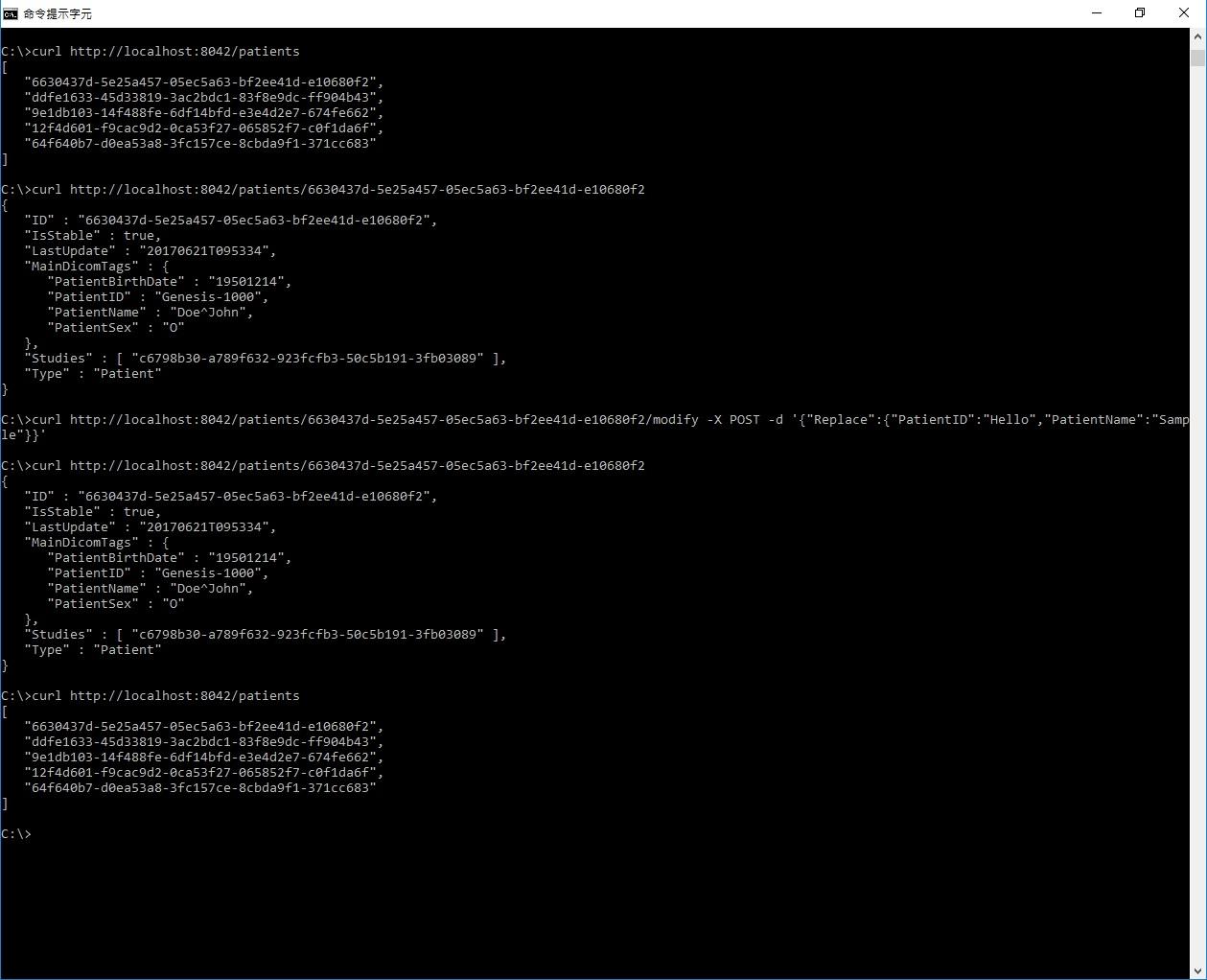
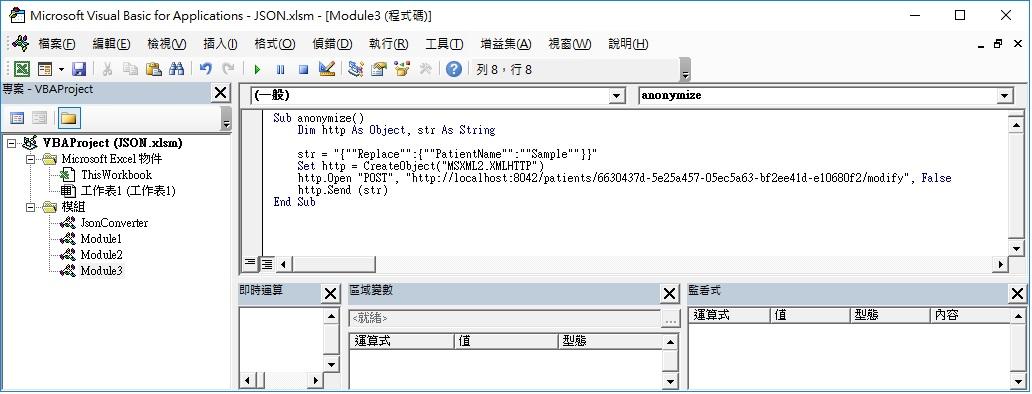
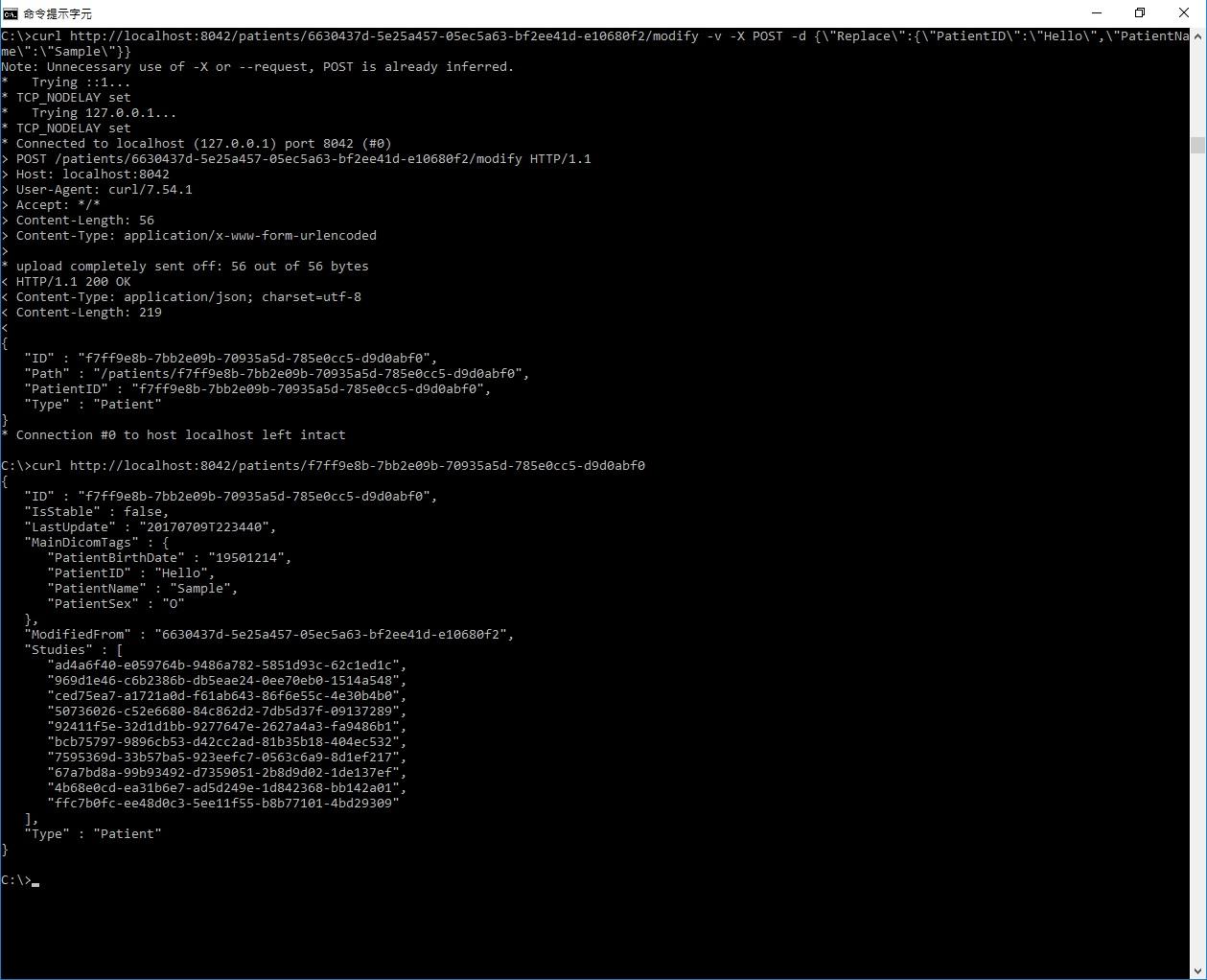
I usually receive DICOM files in which the PatientName was encoded in Big5 character set. Since Big5 is not supported in most viewers/server, patients' names are not displayed correctly. Thus, I am trying to replace the Big5 PatientNames with UTF-8 ones based on a list of PatientName/PatientID pairs. Initially, I tried to do this with EXCEL VBA, the tool I am more familiar with. With EXCEL VBA, I can "GET" patients information successfully, but failed to modify the PatientName tag with HTTP POST. Then, I tried curl. with which, I can get patients information as well, but failed to modify either. The picture attached are my VBA code and the command line I used with curl. Can some please help me out of this? Thanks a lot!
Environment:
Windows 10 pro 64bit
ORTHANC V1.2
Curl 7.54.1 64bit
Just solved the problem myself after googling more about curl and POST.
I replaced "" with \" and removed the outer ' in the JSON text. Based on the info from -v, the use of -X seemed unnecessary.
In the session MODIFICATION of PATIENTS, the instruction says "Please note that, in this case, you have to set the value of the PatientID (0010,0020) tag for Orthanc to accept this modification: This is a security to prevent the merging of patient data before and after anonymization, if the user does not explicitly tell Orthanc to do so."
However, in my case, I simply want to change the PatientName tag. To do so, I have to:
1. create a whole new set of Dicom files with a slightly modified PatientID,
2. delete the old set of Dicom files with the original PatientID,
3. create another new set of Dicom files with target PatientName and original PaitentID.
4. delete the set of Dicome files with the slightly modified PatientID.
Is there any easier way to modify PatientName or other tags without creating a new set of files? Without creating a new set, there is no chance "merging of patient data before and after anonymization".
Of course a more sensible way, I think, is to allow users to assign PatientName and other tags while importing Dicom files.
Well, I think you might have found a bug in the /patients/…/modify route.
Indeed, when you follow the book recommendation (as you do), and re-use the same PatientID as the original one, Orthanc will modify all instances of the patient with the new PatientName. All studies will appear twice in Orthanc, once with the old PatientName and once with the new PatientName. These 2 studies are attached to a patient that has not been renamed.
Yes, the 4-step method works well for me. I also tried the LUA scripts from the ORTHANC book, which are capable of finishing the rename modification when a DICOM image is stored. I love this method. The LUA codes are much simpler. No need to identify the ID in the first place. Less disk space usage. And probably saves time.
However, it works only when a patient's name is coded in ASCII. And in my case, I need utf8. I learned from Google that LUA actually supports utf8 since Ver. 5.3. I am just wondering if there is any chance I can get a utf8 string passed to ORTHANC through LUA. Maybe after a newer version of LUA was adopted by ORTHANC? Or maybe there is another way to do so?
* The picture attached is the LUA script that failed only because a utf8 string was used.
Regarding UTF-8 strings inside Lua, this already works with Orthanc 1.2.0. You will find a sample Lua script attached to this post. IMHO, your instance of Notepad++ does not write your file using UTF-8 encoding.
Thank you for the utf8.lua script. I tried this script. I opened it in Notepad++, made minimal changes, and saved it to utf8_2.lua. Still, the modified script was functional except the Chinese character part (replace['PatientName'] = '姓名'). I have no idea why. Any suggestion?
Back to this old thread, I confirm that your Lua script works fine with recent versions of Orthanc. This was most probably resolved by Orthanc 1.5.5, that was precisely focused on Asian encodings.
Here is your sample script:
function OnStoredInstance(instanceId, tags, metadata)
if (metadata[‘ModifiedFrom’] == nil and
metadata[‘AnonymizedFrom’] == nil) then
local replace = {}
replace[‘PatientName’] = ‘姓名’
local remove = {}
ModifyInstance(instanceId, replace, remove, true)
Delete(instanceId)
end
end
Note that Orthanc won’t modify the encoding of the file, i.e. the “Specific Character Set” tag (0008,0005) will not change. If the encoding of the source DICOM file doesn’t support Chinese characters, the “PatientName” would have been set to the empty string.